
Challenge #5: Lack of Multiple Data Source Support
With this blog entry, we have reached the final chapter of the Hadoop challenge series. In this blog, I am going to discuss the fifth challenge for current Hadoop implementations – the lack of multiple data source support.
The current Hadoop implementation does not support multiple data sources; instead, it supports only one distributed file system at a time, the default being the Hadoop Distributed File System (HDFS). This restriction creates barriers for organizations whose data is stored in different file systems other than HDFS while implementing MapReduce applications in Hadoop. For non-HDFS users, enabling MapReduce applications running in Hadoop environment means they have to first move their data from the current file system into HDFS, which can turn into a timing consuming and very expensive operation. This limited capability for heterogeneous data support also leads to inferior performance and poor resource utilization due to an inflexible infrastructure.
The reality is, users want a platform that 1) supports various types of input data at the same time and outputs to their desired data sources (which could be different from the input type); 2) completes the data conversion at runtime so no extra ETL steps are needed after the run. (See the chart below for a high-level architecture layout for heterogeneous data support.) For instance, a user can send his input data stored in HDFS and output to a relational database such as Oracle and MySQL upon the completion of the run. Such capabilities eliminate the data movement at both the beginning and the final stages of a MapReduce run, therefore, dramatically reducing the cost while improving the operation efficiency and driving faster time to results.
A high level diagram on heterogeneous data support
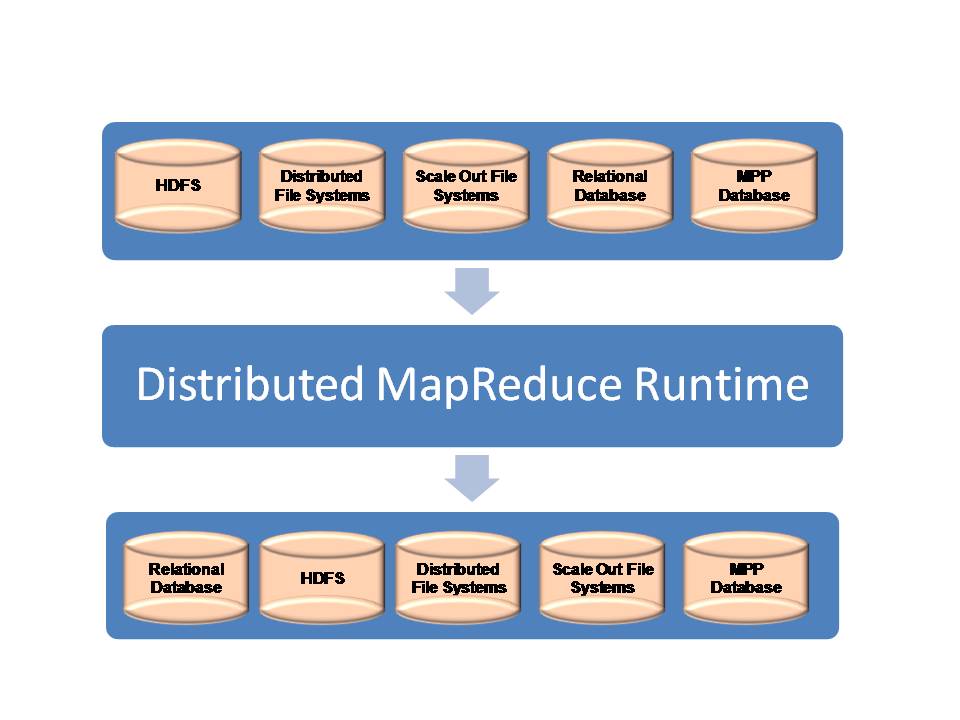
This capability of heterogeneous data support in runtime can be considered as an alternative approach to traditional ETL function. The advantage of the former, while compared with the existing ETL tools, is that it provides a faster, cheaper and integrated new platform for users running Big Data applications.
Having identified the 5 major challenges in the current Hadoop MapReduce implementation, we at Platform Computing has developed a solution – Platform MapReduce, an enterprise-class distributed runtime engine to not only address those barriers mentioned in this blog series, but also bring additional capabilities requested by users wanting to move their Big Data applications into production. For detailed features and benefits delivered by Platform MapReduce, please visit: http://www.platform.com/mapreduce
Please join us at SC11 for a free breakfast briefing: “Overcoming Your MapReduce Barriers”. Register today to secure your spot!
0 comments:
Post a Comment